
![[Python] KMP 알고리즘으로 문자열 찾기](https://images.unsplash.com/photo-1517336714731-489689fd1ca8?ixlib=rb-1.2.1&q=80&fm=jpg&crop=entropy&cs=tinysrgb&fit=max&ixid=eyJhcHBfaWQiOjExNzczfQ&w=2000)
들어가면서
KMP(Knuth, Morris, Pratt) 알고리즘은 찾고자 하는 문자열(Pattern)을 주어진 문자열(Text)에서 빠르게 찾아내는 방법 중 하나입니다. KMP의 강력함을 알기 위해서 먼저 가장 쉽게 문자열 탐색을 하는 알고리즘 중 하나인 브루트 포스(Brute force)방법을 이용해 문자열을 찾아내는 예제를 확인해보겠습니다. 편의상 원하는 문자열을 찾으면 반복문을 종료하도록 했습니다.
target = 'ABC'
text = 'ABABCA'
for i in range(len(text)-len(target)):
for j in range(len(target)):
if text[i+j] == target[j]:
j+=1
else:
break
print('Identified')
break
위 알고리즘대로 찾는다면 최악의 경우 (Pattern의 길이) * (Text의 길이) 만큼 반복됩니다. 만일 Pattern의 길이를 K, Text의 길이를 N이라고 하면 Brute force 알고리즘의 시간 복잡도는 O(NK)와 같이 나타납니다. 두 문자열이 길수록 연산량은 말 그대로 "기하급수적"으로 늘어나게 됩니다.
KMP(Knuth, Morris, Pratt) 알고리즘
그래서 효율적인 검색을 위해 KMP 알고리즘이 등장하게 됩니다. 이 알고리즘을 본격적으로 알아보기 전에 우리가 찾고자 하는 문자열인 Pattern을 전처리하는 과정이 필요합니다.
Preprocessing of the pattern
Degenerate pattern
Degenerate pattern이란 어떤 패턴 속에 있는 작은 패턴이 한 번 이상 반복되는 현상을 말합니다. 예를 들면 다음 문자열
ABABAB
은 AB가 반복되고 있습니다. 이렇게 전체 패턴 안에 작은 패턴이 반복되는 경우를 Degenerate pattern이라 합니다. KMP 알고리즘은 문자열의 Degenerate pattern을 이용하여 빠른 검색을 하도록 만든 알고리즘입니다.
Pi array, LPS(Longest proper prefix which is suffix)
이를 이용하기 위해서 Pi 배열, 또는 LPS 배열이라는 것을 도입하게 됩니다. 먼저 Prefix(접두어)와 Suffix(접미어)의 개념을 알아봅시다.
ABX
위 문자열에서 Prefix는 A, AB가 가능하고, Suffix는 X, BX가 됩니다.
ABXAB
마찬가지로 위 문자열에서 Prefix는 A,AB,ABX, ABXA이고, Suffix는 B,AB,XAB,BXAB가 됩니다. 이 중에서 Prefix가 Suffix와 같은 경우는 AB입니다.
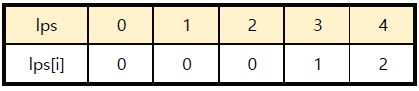
LPS는 Prefix와 Suffix가 같은 경우 중 가장 길이가 긴 경우를 말합니다. 이 배열의 개념은 예제를 통해 이해하는 것이 수월합니다. 본격적으로 LPS를 만들어 보겠습니다. 같은 문자열 예제를 사용합니다.
pat='ABXAB'
| index | substring | lps[index]의 값 | 설명 |
| 0 | A | 0 | Prefix와 Suffix가 없으므로 0입니다. |
| 1 | AB | 0 | Prefix와 Suffix가 일치하지 않으므로 0입니다. |
| 2 | ABX | 0 | Prefix와 Suffix가 일치하지 않으므로 0입니다. |
| 3 | ABXA | 1 | A가 일치하므로 1입니다. |
| 4 | ABXAB | 2 | AB가 일치하므로 2입니다. |
이를 정리하여 배열을 만들면 다음과 같습니다.
lps = [ 0, 0, 0, 1, 2 ]
여기서 눈여겨봐야 할 것은 lps[3]과 lps[4]입니다. lps[3]=1이라는 것의 의미는 1길이의 Prefix와 Suffix가 동일하다는 점입니다.

따라서 lps[4]를 구할 때에는 pat[0]==pat[3]이므로 pat[1]과 pat[4]만 비교해보면 됩니다.
이 과정을 코드로 나타내면 다음과 같습니다.
def computeLPS(pat, lps):
leng = 0 # length of the previous longest prefix suffix
# 항상 lps[0]==0이므로 while문은 i==1부터 시작한다.
i = 1
while i < len(pat):
# 이전 인덱스에서 같았다면 다음 인덱스만 비교하면 된다.
if pat[i] == pat[leng]:
leng += 1
lps[i] = leng
i += 1
else:
# 일치하지 않는 경우
if leng != 0:
# 이전 인덱스에서는 같았으므로 leng을 줄여서 다시 검사
leng = lps[leng-1]
# 다시 검사해야 하므로 i는 증가하지 않음
else:
# 이전 인덱스에서도 같지 않았다면 lps[i]는 0 이고 i는 1 증가
lps[i] = 0
i += 1
코드로 나타내니 다시 어려워졌죠? 차근차근 이해해봅시다.

먼저 lps[0]==0이므로 while문은 i==1부터, leng==0으로 시작합니다.

i=1일때는 pat[0:1] = AB이므로 pat[i] == pat[leng]은 False입니다. 그 다음, lps==0이므로 lps[1]=0을 대입합니다. 다음 인덱스로 넘어가기 위해 i를 1 증가시킵니다.

i=2일때는 pat[0:2] = ABX이므로 i=1일때와 동일합니다. lps[2]=0입니다.
i=3일때는 pat[0:3] = ABXA이므로 pat[3] == pat[0]입니다. 따라서 leng은 1을 증가시켜주고, lps[3]=1이 됩니다. i도 1을 증가시켜줍니다.
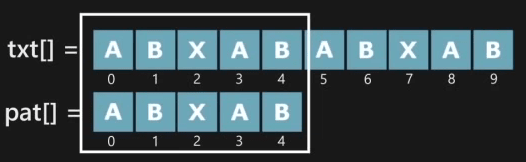
i=4일때는 pat[0:4] = ABXAB이므로 pat[4] == pat[1]입니다. 마찬가지로 lps[4]=2가 됩니다. 여기서 pat[3] == pat[0]임을 lps[3]==1으로 저장해놓았기 때문에 그 다음 인덱스만 조사해주면 되는 것입니다.
이게 무슨 말이냐면, 만일 주어진 pattern이 ABXAA였다면 pat[4] != pat[1]이지만 leng !=0이므로 두번째 if문에 해당하게 됩니다. 여기서 leng = lps[leng-1]때문에 leng==0이 됩니다. 인덱스를 증가시키지 않았으므로 다시 while문으로 돌아오게 되고, pat[4] == pat[0]을 검사하게 되고, 참이므로 leng==1, lps[4]=1이 됩니다. 이해가 되시나요? 이해가 어렵다면 해당 부분을 지우고 코드를 실행시켜보고, 어떤 부분 때문에 에러가 발생하는지 찾아보시기 바랍니다.
KMP Search
LPS배열의 개념이 어려우셨죠? 저도 이해하는 데 한참 걸렸습니다. KMP 알고리즘은 LPS배열을 만드는 과정과 굉장히 비슷합니다. 일단 아까 만들어준 LPS배열을 여기 박아놓고 시작합시다.

아까도 계속 강조했듯이, lps[]의 값은 다음에 조사할 인덱스를 정하는 기준이 됩니다. 다시 말하면, 이미 Pattern의 일부와 같다는 것을 알고 있는 부분은 다시 조사하지 않고 넘어간다는 것입니다. 다시 위의 Pattern을 가지고 Text와 비교해볼까요?

각 문자열의 인덱스 0부터 비교를 시작합니다. 이 경우에는 인덱스 0 에서 Pattern이 검출되었습니다. 그리고 LPS 배열의 길이는 이 경우 AB이므로 lps[4]=2입니다.
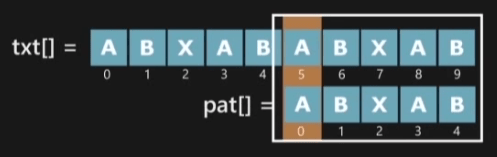
따라서 검사를 Text의 인덱스 4의 다음인 5에서 시작하고, 검사를 시작할 Pattern의 인덱스는 2가 됩니다.
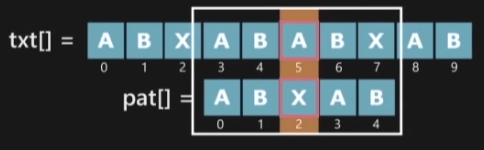
하지만 여기서 검사한 문자가 일치하지 않으므로 Pattern의 바로 이전 인덱스의 LPS값인 lps[1]=0를 참조합니다. 따라서 Pattern은 인덱스 0부터 Text와 비교하게 됩니다. 이때 Pattern이 다시 검출되어 검색이 완료됩니다. 이 내용을 코드로 살펴보면 다음과 같습니다.
def KMPSearch(pat, txt):
M = len(pat)
N = len(txt)
lps = [0]*M
# Preprocess the pattern
computeLPS(pat, lps)
i = 0 # index for txt[]
j = 0 # index for pat[]
while i < N:
# 문자열이 같은 경우 양쪽 인덱스를 모두 증가시킴
if pat[j] == txt[i]:
i += 1
j += 1
# Pattern을 찾지 못한 경우
elif pat[j] != txt[i]:
# j!=0인 경우는 짧은 lps에 대해 재검사
if j != 0:
j = lps[j-1]
# j==0이면 일치하는 부분이 없으므로 인덱스 증가
else:
i += 1
# Pattern을 찾은 경우
if j == M:
print("Found pattern at index " + str(i-j))
# 이전 인덱스의 lps값을 참조하여 계속 검색
j = lps[j-1]
코드로 보니까 LPS를 계산할 때와 정말 비슷하지 않나요? LPS 배열을 만드는 방법을 이해하셨다면 위 코드를 이해하기 어렵지 않을 것입니다. 실행 가능한 전체 코드를 첨부해 드릴테니 직접 테스트해보세요.
def KMPSearch(pat, txt):
M = len(pat)
N = len(txt)
lps = [0]*M
# Preprocess the pattern
computeLPS(pat, lps)
i = 0 # index for txt[]
j = 0 # index for pat[]
while i < N:
# 문자열이 같은 경우 양쪽 인덱스를 모두 증가시킴
if pat[j] == txt[i]:
i += 1
j += 1
# Pattern을 찾지 못한 경우
elif pat[j] != txt[i]:
# j!=0인 경우는 짧은 lps에 대해 재검사
if j != 0:
j = lps[j-1]
# j==0이면 일치하는 부분이 없으므로 인덱스 증가
else:
i += 1
# Pattern을 찾은 경우
if j == M:
print("Found pattern at index " + str(i-j))
# 이전 인덱스의 lps값을 참조하여 계속 검색
j = lps[j-1]
def computeLPS(pat, lps):
leng = 0 # length of the previous longest prefix suffix
# 항상 lps[0]==0이므로 while문은 i==1부터 시작한다.
i = 1
while i < len(pat):
# 이전 인덱스에서 같았다면 다음 인덱스만 비교하면 된다.
if pat[i] == pat[leng]:
leng += 1
lps[i] = leng
i += 1
else:
# 일치하지 않는 경우
if leng != 0:
# 이전 인덱스에서는 같았으므로 leng을 줄여서 다시 검사
leng = lps[leng-1]
# 다시 검사해야 하므로 i는 증가하지 않음
else:
# 이전 인덱스에서도 같지 않았다면 lps[i]는 0 이고 i는 1 증가
lps[i] = 0
i += 1
# 조금 더 긴 텍스트
# txt = "ABABDABACDABABCABAB"
# pat = "ABABCABAB"
# 본문에서 다룬 예제
txt = 'ABXABABXAB'
pat = 'ABXAB'
KMPSearch(pat, txt)
# This code is contributed by Bhavya Jain