

Agenda
- Cgruops란? 그리고 Docker의 cgroups 옵션
- CFS 스케줄러란?
- Mesos 프레임워크에서 CFS 스케줄러와 cgroups 옵션의 이해
cgroups
cgroups란?
cgroups는 Control groups의 약자로, 리눅스 시스템에서 동작하는 모든 프로세스들의 리소스 사용량을 감시하고 제어하는 등의 역할을 수행합니다. 이 중 사용자 입장에서 가장 큰 부분이 바로 리소스 사용량을 제한하거나 우선순위(priority)를 부여하는 역할입니다. 여기에서 말하는 리소스 중에서 대표적인 것들은 다음과 같습니다.
- CPU
- Memory
- Network
- Disk
cgruops는 /sys/fs/cgroup/ 폴더에 가상 파일(virtual file)로 존재합니다.
/sys/fs/cgroup/cpu,cpuacct $ ls
cgroup.clone_children cpu.rt_period_us cpuacct.usage cpuacct.usage_sys release_agent
cgroup.procs cpu.rt_runtime_us cpuacct.usage_all cpuacct.usage_user system.slice
cgroup.sane_behavior cpu.shares cpuacct.usage_percpu docker tasks
cpu.cfs_period_us cpu.stat cpuacct.usage_percpu_sys init.scope user.slice
cpu.cfs_quota_us cpuacct.stat cpuacct.usage_percpu_user notify_on_release
/sys/fs/cgroup/cpu,cpuacct $ cat cpu.stat
nr_periods 0
nr_throttled 0
throttled_time 0
이 중 cpu.stat 파일에서 현재 속한 cgroup의 cpu 관련 정보를 볼 수 있습니다.
nr_periods: 현재 cgroup의 쓰레드가 지금까지 실행된 횟수, 스케줄러 사이클 횟수nr_throttled: 프로세스가 할당된 time quota를 모두 사용하고 throttle 된 횟수throttled_time: 개별 스레드가 throttle된 전체 시간의 합
이 값들이 실제로 어떤 의미를 갖는지를 이해하기 위해서는 다음 섹션의 CFS 스케줄러를 먼저 이해해야 합니다.
CPU cgroups
cgroups를 사용하면 특정 프로세스의 CPU 사용량을 제한할 수 있습니다. 예를 들어, CPU에 부하를 주는 stress 프로세스에게 전체 CPU의 25%만 사용하게끔 할 수 있습니다.
systemd-run -p CPUQuota=25% stress --cpu 3이러한 CPU 리소스를 할당해주는 옵션은 두 가지가 있습니다.
- CPUQuota : hard limit (ceiling), default 100%
- CPUShares : soft limit (floor), default 1024
CPUShares는 다른 프로세스가 있어야만 의미를 가지는 값입니다. 만일 시스템에 단일 프로세스로 동작하는 경우는 항상 100% CPU 사용량을 가지게 됩니다. 단, 실제로 모든 코어를 100% 사용한다는 의미가 아닌, CPU를 사용할 수 있는 시간의 비율이 100%라는 의미입니다. 시스템에 1개의 프로세스만 있다면 당연히 모든 CPU시간을 쓸 수 있겠죠?
만약 다른 프로세스가 CPUQuota=25%옵션으로 실행된다고 생각해 보겠습니다. 그러면 원래 있던 프로세스는 75%를, 새로 시작된 프로세스가 25%의 CPU 시간을 점유할 것입니다. 그렇기 때문에 CPUShares 가 soft limit, CPUQuota가 Hard limit 가 됩니다.
CFS 스케줄러
CFS의 개념
CFS는 Completely Fair Scheduler의 약자로, 2007년 배포된 커널 버전 2.6.23 이후의 공식 스케줄러입니다. CFS는 프로세서의 시간을 모든 프로세스들에 공평하게 분배하는 방식을 사용합니다. CFS는 Heuristics 없이 공평하게 시간을 분배하고, I/O 또는 CPU bound 프로세스들을 잘 처리한다는 특징을 가지고 있습니다.
CFS의 작동 원리를 이해하려면 몇 가지 개념을 짚고 넘어가야 합니다.
- Time slice : 스케줄러가 특정 프로세스에 할당하는 실행 시간을 의미합니다.
- Virtual runtime : 흔히
vruntime이라고 부르고, 프로세스가 지금까지 실행된 시간을 의미합니다. 이 값은 단조 증가하는 특징을 가지는데, 왜냐하면 이 값이 아래와 같이 계산되기 때문입니다.
$$
vruntime += \dfrac{\text{execution time of current cycle}}{\text{weight based on priority}}
$$
vruntime의 의미는 다음 섹션에서 자세히 알아보겠습니다.- Prority : OS 내부적으로 크리티컬하게 동작하는 "실시간" 프로세스들은 절대 다른 프로세스에 의해서 block되면 안되기 때문에 높은 우선순위를 가져야 합니다. 이에 해당되지 않는 유저 프로세스들은 이보다 낮은 우선순위를 가지며, batch로 실행되거나 I/O에 bound되는 경우가 많습니다. 결론적으로, Realtime process들은 0~99의 우선순위를, 유저 프로세스들은 100~139의 우선순위를 가지고 있습니다.
CFS 아이디어
CFS는 Red-Black Tree(RB Tree)라는 자료구조를 이용해 구현되어 있습니다. RB Tree의 특징은, 가장 작은 값을 갖는 노드가 반드시 가장 왼쪽에 위치한다는 점입니다. CFS에서 이 노드의 값이 바로 vruntime입니다. 조금 감이 오시나요?
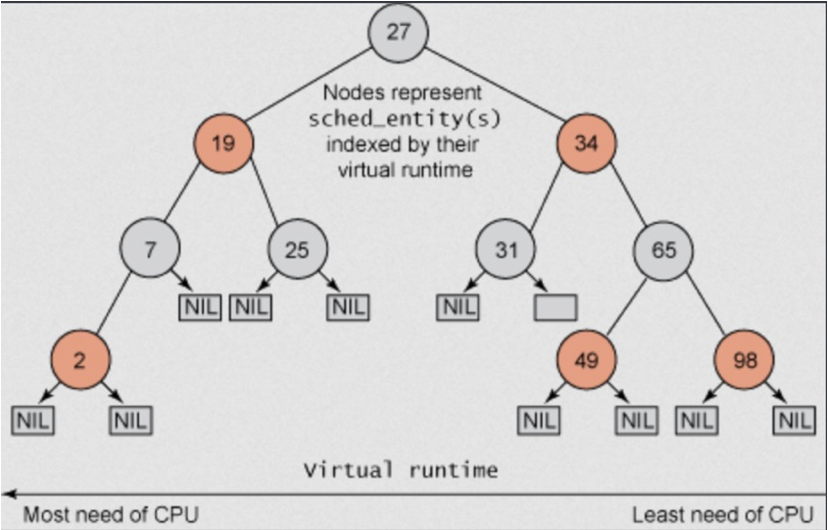
스케줄러는 특정 시간마다 RB Tree의 가장 왼쪽 노드(이 노드를 가리키는 포인터가 바로 ptr min_vruintime)를 찾은 다음, 해당 노드에 해당하는 프로세스를 실행합니다. 프로세스는 실제 실행된 시간만큼 vruntime이 증가되고, 프로세스가 종료되지 않았다면 다음 사이클에서 해당 프로세스를 실행시키기 위해서 RB Tree 중간쯤으로 노드를 이동시킵니다. 이렇게 한 사이클이 진행되고, 다음 사이클이 진행되면 가장 작은 vruntime을 갖는 프로세스가 선택되고, 실행된 다음 노드 중간으로 이동됩니다.
실제로는 실제 실행 시간에 중요도에 따른 Weight이 함께 계산되어 vruntime 을 증가시킵니다.왜 CFS는 RB Tree로 구현되었을까요?
- 위에서도 살펴보았듯이, 가장 작은 값을 갖는 노드가 반드시 트리의 가장 왼쪽에 위치합니다. 즉 다음 사이클에서 실행된 프로세스를 $O(1)$ 시간에 찾을 수 있습니다.
- Self balancing 트리이기 때문입니다. 트리 상의 어떤 경로도, 다른 경로보다 두 배 이상 길 수 없습니다. 즉, 루트 노드로부터 좌/우 서브트리의 길이가 비슷하게 유지된다는 특징을 가집니다.
- 어떤 노드를 삽입하거나 삭제하는데 걸리는 시간이 항상 $O(\log{n})$입니다.
CFS에 대해서 더 자세한 내용이 궁금하시다면, 아래의 튜토리얼을 참고하세요.


