

1편:

Agenda
- Cgruops란? 그리고 Docker의 cgroups 옵션
- CFS 스케줄러란?
- Mesos 프레임워크에서 CFS 스케줄러와 cgroups 옵션의 이해
CFS example
CFS 스케줄러를 이용해 프로세스를 스케줄 해보겠습니다.
본 예제의 그림은 다음 포스팅에서 가지고 왔습니다: CPU Throttling - Unthrottled: How a Valid Fix Becomes a Regression
기본적으로 CFS가 다음 작업을 수행하도록 하는 사이클인 Default CFS period는 100,000ns == 100ms 입니다. 이 값은 아래와 같이 확인할 수 있습니다.
/sys/fs/cgroup/cpu,cpuacct $ cat cpu.cfs_period_us
100000
CPU 코어가 1개뿐인 가상의 리눅스 머신을 생각해 보겠습니다. 여기에 200ms의 런타임이 필요한 프로세스 하나를 실행해 보겠습니다. 이 프로세스는 다른 제한조건이 없고, 다른 프로세스가 없는 상태에서 실행됩니다. 그러면 200ms의 시간을 온전히 프로세스 수행에 사용할 수 있습니다.
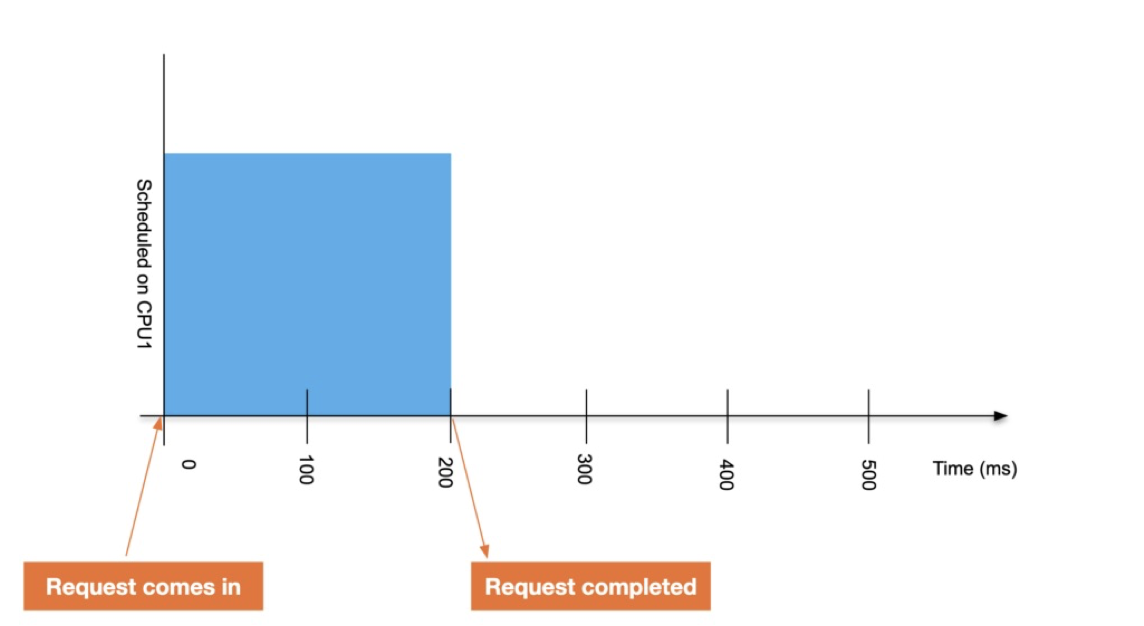
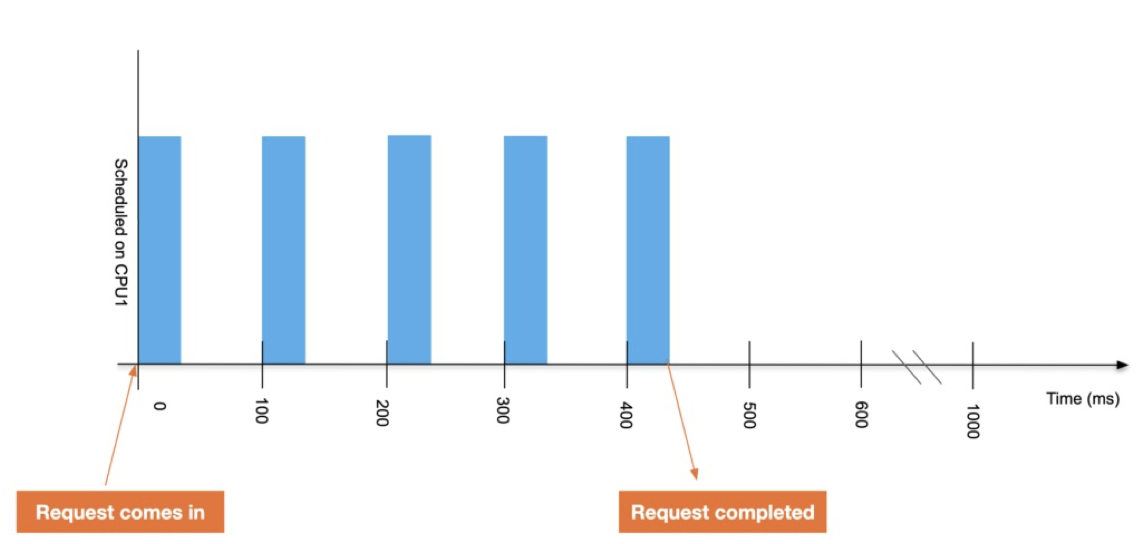
여기서 이 프로세스의 CPUQuota 를 0.4로 둔 상태로 실행한다면 이 프로세스는 스로틀(throttled)됩니다. 아래 그림처럼 한 사이클(100ms) 중에서 40ms밖에 실행되지 않기 때문에 총 5번의 사이클을 돌아야 200ms의 실행시간을 채울 수 있게 됩니다.
만일 프로세스 2개를 CPUShares=512 옵션으로, 즉 각 프로레스당 0.5CPU를 할당해 실행하면 어떻게 될까요? 아래처럼 100ms 구간을 반씩 나누어 실행되는 것을 알 수 있습니다. 이 경우에는 한 사이클당 50ms씩 실행되기 때문에 200ms 실행시간을 맞추기 위해서 총 4 사이클을 반복하게 됩니다.

실제로 운영체제에서 실행되는 수많은 프로세스들이 이처럼 짧은 CPU 시간을 할당받아 작업을 수행하고 멈추는 것을 반복하면서 실행되고 있습니다. 다만 이 사이클이 굉장히 빠르고, 현대의 컴퓨터들은 대부분 멀티코어 CPU에서 동작하기 때문에 사용자 입장에서는 계속 동작하는 것처럼 보이게 됩니다.
Example with docker
도커를 사용할 때 cgrops가 어떻게 작동하는지 알아보겠습니다. 리눅스 입장에서 도커 컨테이너는 하나의 프로세스로 동작하는 것이기 때문에 다른 프로세스와 마찬가지로 cgroups가 동일하게 적용됩니다. 또한, 컨테이너 내부에서 실행되는 서브프로세스들 또한 컨테이너의 하위 프로세스라서 해당 컨테이너와 같은 cgroups가 적용됩니다.
도커 컨테이너에 CPU cgroups 옵션을 주려면, 다음의 두 플래그를 사용합니다.
--cpu-shares: default 1024--cpu-quota: default 100000 microseconds
stress 컨테이너 두개를 각각 512 cpu shares를 가지고 실행해 보겠습니다.
docker run --rm --cpu-shares 512 polinux/stress stress --cpu 48 --timeout 60
docker run --rm --cpu-shares 512 polinux/stress stress --cpu 48 --timeout 60
각 cgroups가 얼만큼의 CPU를 사용하고 있는지를 보려면, top이나 htop과 같은 시스템 모니터로는 보기가 불편합니다. 따라서 cgroups 별로 통계를 보여주는 systemd-cgtop 를 사용합니다. 현재 실행되고 있는 각 컨테이너는 아래와 같이 나타납니다.
Control Group Tasks %CPU Memory Input/s Output/s
/ - 4797.7 199.8G - -
/docker 98 4206.9 122.7G - -
/docker/31c31a6a6516d25ec7438e77d644ccb77ce6d7705a5a924079c2013c8840ce6c 49 2208.6 5.7M - -
/docker/7c4231b904a73b2817d37b2343fd0362d4d7666e00f848d152514ee331e11120 49 1998.6 5.5M - -
두 컨테이너 모두 docker 라는 cgroups 밑에 속해 있는 것을 알 수 있고, 각 컨테이너의 %CPU 도 거의 비슷하다는 것을 알 수 있습니다.
이번에는 cpu share를 각각 1024와 512로 실행해 보겠습니다. 그러면 전체 CPU 시간을 2:1 비율로 나누어서 실행하게 되겠죠?
docker run -d --rm --cpu-shares 1024 polinux/stress stress --cpu 48 --timeout 60
docker run -d --rm --cpu-shares 512 polinux/stress stress --cpu 48 --timeout 60
예상했던 대로, 이번에는 두 컨테이너의 %CPU 비율이 약 2:1로 나타나는 것을 알 수 있습니다. 따라서 CPUShares 옵션이 최소한의 CPU 사용 시간을 보장한다는 것을 확인할 수 있습니다.
Control Group Tasks %CPU Memory Input/s Output/s
/ - 4789.0 200.4G - -
/docker 98 4541.6 122.7G - -
/docker/6c081ae2f4cc5ddf58a0234c184ed2b11ef0b7209140e3c692c6185e1ad32e4e 49 3094.3 6.1M - -
/docker/acad4e643bab731e206313bdbf1fabb9d3f3ba599f2bde392a3ff939cd099ae0 49 1447.3 6.2M - -
Mesos and (CPU) cgroups
메소스 클러스터의 CPU cgroups 기본 옵션은 CPUShares 였지만, >1.10 버전부터는 CPUQuota 로 변경되었습니다. 이 값은 실제로는 /var/lib/dcos/mesos-slave-common 파일에 정의된 슬레이브 옵션에 정의되어 있습니다.
MESOS_CGROUPS_ENABLE_CFS=true
위 옵션이 true 기 때문에, 에이전트에서 실행되는 각 컨테이너가 CFS 스케줄러의 CPUQuota 를 사용해서 CPU를 사용하게 됩니다. (Hard limit)
docker -H unix:///var/run/docker.sock run --cpu-shares 1024 --cpu-quota 100000 --memory 2147483648
만일 옵션을 false 로 바꾸면, 각 에이전트에서 실행되는 컨테이너들은 미리 지정된 CPU 비율에 맞추어 실행되게 됩니다. (Soft limit)
docker -H unix:///var/run/docker.sock run --cpu-shares 1024 --memory 2147483648
주의해야 하는 점은 마스터에서 이 플래그를 설정하는 것이 아니고, 각 에이전트의 슬레이브에서 설정한다는 점입니다.
Effect of CPUQuota
기본적으로 CPUShares 옵션으로 컨테이너들을 실행하게 되면, 다른 프로세스가 에이전트에 실행중이지 않을 경우 할당된 것보다 더 많은 CPU 시간을 사용할 수 있어서 태스크가 더 빨리 종료될 수 있다는 장점이 있습니다. CPUQuota 옵션을 주게 되면 각 컨테이너가 지정된 만큼만 CPU를 사용하게 되며, 다른 프로세스가 있더라도 더 많은 CPU 를 사용할 수 없게 됩니다.
그러나 Mesos가 DC/OS라는 점을 생각해보면, soft limit인 CPUShares 로 작업들을 스케줄하는건 위험한 방법일 수 있습니다. 왜냐하면 각 태스크에 필요한 리소스를 정확하게 가늠하기 어렵고, 매 실행 때마다 다른 결과(특히 실행시간)를 얻을 가능성이 크기 때문입니다. 이러한 이유에서 메소스에서도 CPUQuota를 기본으로 바꾼 것 같습니다.
References
- https://danluu.com/cgroup-throttling/
- linux/sched-design-CFS.rst at master · torvalds/linux · GitHub
- https://goldmann.pl/blog/2014/09/11/resource-management-in-docker/#_cpu
- https://mesosphere.github.io/field-notes/faqs/utilization.html
- https://mesos.apache.org/documentation/latest/isolators/cgroups-cpu/


