

연속랜덤변수(Continuous random variables)
연속랜덤변수를 이해하기 위해 다음 예시를 살펴보자. 원의 중심에 고정된 상태로 원반 위에 어떤 화살표를 회전시키고, 기준으로부터 측정한 각도 $\theta$를 랜덤변수로 두었다. 이 경우 $\theta$는 0부터 $2\pi$의 범위를 연속적으로 가지게 된다. 이를 실선으로 나타낸 것이 오른쪽의 그림이다.
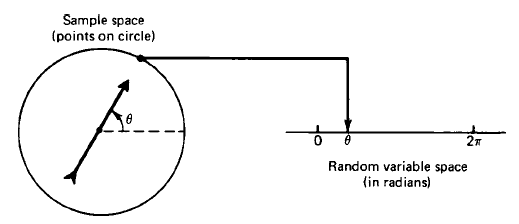
이때 표본공간은 화살표가 나타낼 수 있는 각도인 0부터 $2\pi$까지의 실수(Real number)다.
확률밀도함수(Probability density function)
따라서 어떤 범위 $\theta_1<\theta<\theta_2$ 안에 있을 경우의 확률을 식으로 나타내면 다음과 같다.
$$
P(\theta_1<X<\theta_2)=\int_{\theta_!}^{\theta_2}{f_X(\theta)}d\theta
$$
이때 X는 랜덤변수이고, $f_X$는 확률밀도함수이다. 위 식으로부터 다음과 같은 식을 유도할 수 있다. 먼저 화살표가 특정 지점을 가리키는 경우는
$$
f_X(\theta)=\frac{1}{2\pi},\ 0\leq \theta \leq2\pi
$$
이므로 표본공간 전체에 대한 확률은
$$
\int_0^{2\pi}{f_X(\theta)d\theta}=1
$$
이 된다. 위로부터 확률분포함수(Probability distribution function)을 정의할 수 있다.
$$
F_X(x)=\int_0^{x}{f_X(\theta)d\theta}
$$
확률밀도함수와 확률분포함수를 그래프로 나타내면 다음과 같이 나타난다.
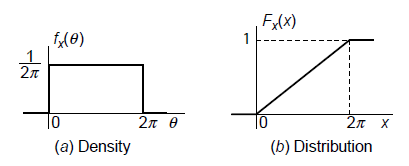
위의 예시에서 화살표는 0부터 $2\pi$ 사이의 어느 점이나 가리킬 수 있으므로 균등한 확률밀도를 가지게 된다. 그리고 확률밀도함수를 0부터 $x$까지 적분한 것이 확률분포함수이므로, 위 예시의 경우에는 확률분포함수가 일정하게 증가하는 개형을 가지게 된다.
두 함수의 관계가 미분-적분 관계를 가지기 때문에 상황에 따라서 둘 중 하나만 가지고도 어떤 표본공간의 확률변수를 정확히 나타낼 수 있다. 그런데 두 함수의 약자가 모두 "pdf"이어서 일반적으로 확률밀도함수를 pdf로, 확률분포함수를 PDF로 나타낸다.
기대값(Expectation), 평균값(Average), 특성함수(Characteristic Function)
어떤 데이터가 주어졌을 때, 그 데이터를 대표할 수 있는 어떤 값을 정하는 방법에는 여러 가지가 있다. 이번 섹션에서는 랜덤변수를 대표할 수 있는 값을 구하는 방법에 대해서 알아본다.
랜덤변수의 평균은 유한 번의 시행을 통해 얻어낸 평균이기 때문에 표본평균(Sample mean)이라고 부르며, 다음과 같이 계산한다.
$$
\bar{X}=\frac{X_1+X_2+\cdots+X_N}{N}
$$
$\bar{X}$가 평균이고, $X_1, \cdots, X_N$은 반복 시행으로부터 얻어진 표본들이다.
그런데 만일 시행을 무한 번 반복한다면 실제 평균값에 가까운 값을 얻을 수 있을 것이다. 실제로는 무한 번 반복할 수 없기 때문에, 각 표본이 발생할 확률을 이용해 기대값(Expectation)을 계산한다. 여러 번의 시행을 통해 얻어질 수 있는 표본을 $x_1, x_2, \cdots, x_n$이라고 하고, 각 표본이 나타날 확률을 $p_1, p_2, \cdots, p_n$이라고 나타낼 수 있다. 충분히 큰 수인 N번만큼 시행을 하면, 각 표본이 발생하는 수는 $p_1N, p_2N, \cdots, p_nN$이라고 할 수 있다. 따라서 표본평균을 구하면 다음과 같다.
$$
\bar{X}_{sample}\approx\frac{(p_1N)x_1+(p_2N)x_2+\cdots+(p_nN)x_n}{N}
$$
이렇게 구한 평균을 기대값이라고 부르며 다음과 같이 정의한다.
$$
E[X]=\sum_{i=1}^n{p_ix_i}
$$
비슷한 방법으로 연속랜덤변수에 대해서도 기대값을 다음과 같이 정의할 수 있다.
$$
E[X]=\int_{-\infty}^{\infty}{xf_X(x)}dx
$$
또한, 다음과 같이 일반화된 정의를 구성할수도 있다.
$$
E[g(X)]=\sum_{i=1}^n{p_ig(x_i)}\\\E[g(X)]=\int_{-\infty}^{\infty}{g(x)f_X(x)}dx
$$
그리고 많은 경우, 랜덤변수 $X$의 N차 모멘트($N$th moment of X)를 $g(X)=X^k$인 경우로 정의한다.
$$
E[X^k]=\int_{-\infty}^{\infty}{x^kf_X(x)}dx
$$
따라서 1차 모멘트는 평균, 또는 기대값 그 자체이다. 여기서 중요한 점은, $X$와 평균의 2차 모멘트는 분산(Variance)이 된다.
$$
\begin{aligned}
\text{Variance of X}&=E\bigg[\Big(X-E[X]\Big)^2\bigg]\\\
&=E\bigg[X^2-2X\cdot E[X]+E[X]^2\bigg]
&=E[X^2]-\big(E[X]\big)^2
\end{aligned}
$$
마지막으로 분산의 제곱근은 표준편차(Standard deviation)이다.
$$
\sigma_X=\sqrt{Var[X]}
$$
정규, 가우시안 확률변수(Normal or Gaussian RV)
확률 변수 X는 다음과 같은 pdf를 가지면 정규 또는 가우시안 확률변수라고 부른다.
$$
f_X(x)=\frac{1}{\sqrt{2\pi}\sigma}\exp\bigg[{-\frac{1}{2\sigma^2}(x-m_X)^2}\bigg]
$$
이때 $\sigma^2$와 $m_X$는 각각 X의 분산과 평균이다.
$$
m_X=\int_{-\infty}^{\infty}xf_X(x)dx\\\
\sigma^2=\int_{-\infty}^{\infty}(x-m_X)^2f_X(x)dx
$$
우리는 여기서 정규확률변수에 대해 매우 중요한 사실을 발견하게 된다. 그것은 정규확률변수의 pdf는 오직 평균과 분산에 의해서만 결정된다는 것이다. 따라서 정규확률변수는 다음과 같이 표기할 수 있다.
$$
X\sim N(m_X,\sigma^2)
$$
이제 pdf를 적분해 PDF를 계산하면 다음과 같다.
$$
\begin{aligned}
F_X(x)&=\int_{-\infty}^{\infty}f_X(u)du\\\
&=\int_{-\infty}^{\infty}\frac{1}{\sqrt{2\pi}\sigma}\exp\bigg[{-\frac{1}{2\sigma^2}(u-m_X)^2}\bigg]du
\end{aligned}
$$
그런데 이 적분은 Closed-form으로 계산되지 않아서, 근사값을 정리해놓은 표로부터 값을 찾아야 한다. 보통은 컴퓨터로 적분값을 계산하기 때문에 직접 표에서 값을 찾을 일은 그다지 많지 않다. (전공 시험 때 한번 찾아서 풀어봤나? 싶다.)
pdf와 PDF의 그래프를 그리면 다음과 같다.
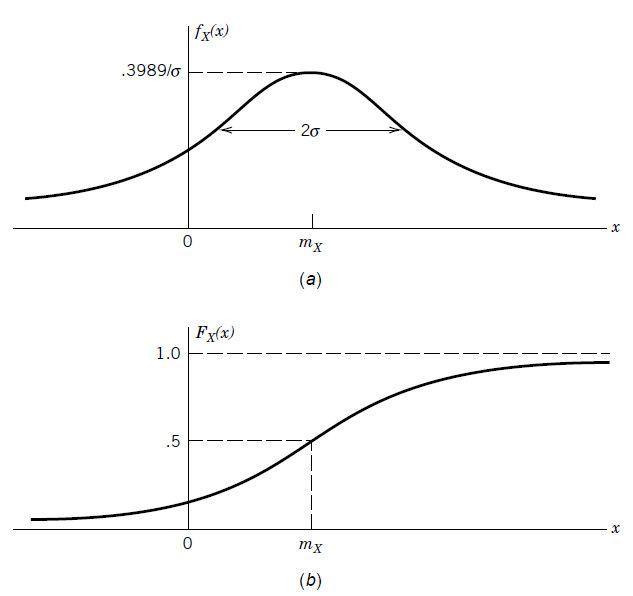
pdf에서도 직관적으로 알 수 있지만, 가장 '그럴듯한' 값은 $m_X$이다. 만일 $\sigma$값이 커지면 그래프는 양옆으로 퍼지게 되고, $\sigma$값이 줄어들면 그래프는 평균을 중심으로 더 모이게 된다.
Joint 연속 확률변수(Continuous RV)
이번 섹션에서는 앞으로 필터링에서 계속 만나게 될 Joint 연속 확률변수에 대해서 다루게 된다. 대부분의 시스템은 2개 이상의 상태변수(State Variable)를 다루게 되므로 변수의 상태를 추정하기 위해서는 필연적으로 Joint 확률을 계산하는 과정이 필요하기 때문이다. Joint 연속 확률변수는 다변수 확률변수(Multivariate RV)라고 부르기도 한다.
확률변수가 1개일 때와 다른 점은 변수의 갯수에 따라 적분식의 중첩이 바뀐다는 것이다. 예를 들어, 확률변수 X와 Y에 대한 PDF는 다음과 같이 계산한다.
$$
F_{XY}(x_0,y_o)=\int_{-\infty}^{y_0}\int_{-\infty}^{x_0}f_{XY}(x,y)dxdy
$$
예를 들어 X, Y가 모두 정규확률변수인 경우를 생각해보자. 이전 섹션에서 공부한 바와 같이, pdf는 다음과 같다.
$$
f_X(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-x^2/2\sigma^2}\\\
f_Y(y)=\frac{1}{\sqrt{2\pi}\sigma}e^{-y^2/2\sigma^2}
$$
두 확률변수가 서로 독립이므로 Joint pdf는 다음과 같이 계산된다.
$$
\begin{aligned}
f_{XY}(x,y)&=\frac{1}{\sqrt{2\pi}\sigma}e^{-x^2/2\sigma^2}\cdot
\frac{1}{\sqrt{2\pi}\sigma}e^{-y^2/2\sigma^2}\
&=\frac{1}{{2\pi}\sigma}e^{-(x^2+y^2)/2\sigma^2}
\end{aligned}
$$
이를 좌표공간에 그려보면 이렇게 나타난다.
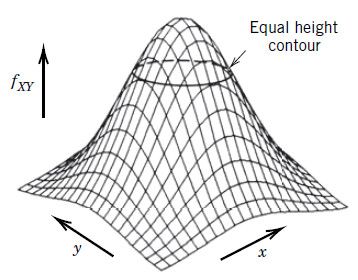
이 그래프는 x, y 방향으로 모두 대칭인 그래프이다. 그래서 xy평면에 평행한 어떤 평면으로 자르더라도 그 단면은 원이 나온다. 마찬가지로 Z축에 평행한 평면으로 자르면, 그 단면은 단순한 정규분포가 나오게 된다.
이전 포스팅에서 베이즈 법칙에 대해서 소개했다. 베이즈 법칙은 확률에 대한 법칙이지만, 연속확률변수에 대해서 그 개념을 확장할 수 있다.
베이즈 법칙
$$
f_{X|Y}=\frac{f_{Y|X}f_X}{f_Y}
$$
조건부 확률밀도
$$
f_{X|Y}=\frac{f_{XY}}{f_Y}\\\
f_{Y|X}=\frac{f_{XY}}{f_X}
$$
독립
확률변수 X, Y가 다음 식을 만족하면 독립 두 확률변수는 독립이다. 그 역도 성립한다.
$$
f_{XY}=f_Xf_Y
$$
Marginal 확률밀도
$$
f_Y=\int_{-\infty}^\infty{f_{XY}(x,y)dx}\\\
f_X=\int_{-\infty}^\infty{f_{XY}(x,y)dy}
$$
여기서 반드시 기억해야 하는 점은 Marginal 확률밀도를 얻으려면 Joint 확률밀도에서 어느 한 변수에 대해서 적분해야 한다는 점이다.
![[Review] VI-DSO (Eng)](https://images.unsplash.com/photo-1552168324-d612d77725e3?ixlib=rb-1.2.1&q=80&fm=jpg&crop=entropy&cs=tinysrgb&fit=max&ixid=eyJhcHBfaWQiOjExNzczfQ&w=1000)
![[Review] Direct Sparse Odometry(DSO) (Eng)](https://images.unsplash.com/photo-1516961642265-531546e84af2?ixlib=rb-1.2.1&q=80&fm=jpg&crop=entropy&cs=tinysrgb&fit=max&ixid=eyJhcHBfaWQiOjExNzczfQ&w=1000)
